管理人の一言

国内のAI狂い
おはよー!国内のAI狂いこと、管理人だよ!2026年も中盤に差し掛かって、AI界隈の熱気はとどまる所を知らないね。今日は特に、エンジニアの間で話題沸騰中の「Qwen3.6」と「ローカル完結型開発」について語っちゃうよ!
最近はClaude4.6やGPT-5みたいな超高性能APIが便利すぎて、ついつい「APIお布施」しがちだったよね。でもね、今起きてるのは「知能の自宅飼育」への大逆転劇なんだ!Qwen3.6っていう中国発の化け物モデルが、ついに「雰囲気コーディング(vibe-coding)」——つまり、細かい仕様を書かなくても雰囲気で察してコードを書き上げる領域で、あのClaudeを超え始めたって噂だよ。
今回の記事では、3090の2枚刺しリグを組んで、月数十万円かかるはずのAPI料金を電気代だけで踏み倒しちゃう(!?)強者たちの実態を深掘りしていくよ。PythonでUnslothのライブラリを叩いてローカルサーバーを立てる楽しさ、みんなにも伝わるといいな!
【Qwen3.6】アリババが開発した2026年時点の最新LLMシリーズ。3.5からアーキテクチャが刷新されて、特にコード生成とツールを自律的に使う『エージェント能力』が爆発的に向上しているよ。
3行でわかる!今回の話題
- Qwen3.6(27B/35B)が「雰囲気コーディング(vibe-coding)」においてClaude4.6等に匹敵する実力を発揮し、ローカル環境への移行が加速している。
- RTX3090の2枚挿し(VRAM48GB)やMacM5Maxなどの構成により、API利用料(1日2万円超)を電気代(数百円)レベルまで圧縮可能に。
- 2026年現在のオープンモデル(Gemma4やQwen3.6)は、旧来の「Llamaの背中を追う」段階を脱し、自律型エージェントとして実用レベルに達している。
1 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)10:00:00 ID:JuChp6oX
Qwen3.6、雰囲気コーディング(vibe-coding)にマジで使えるわ。Claude使うより圧倒的に安い。
ClaudeCodeの接続先をローカルで動かしてるQwen3.6-27B/35Bに変えてみたけど、完璧に動くぞw
昨日からプロジェクト始めたけど、3090の2枚刺しリグでコンテキスト200k設定。
UnslothのQ8版をllama-serverで立てるだけで、
もうAPIにお布施する必要なくなったわ。
プロンプト
【ClaudeCode】
Anthropicが提供している、ターミナル上で動作するAIエンジニア用ツール。本来はClaudeのAPIを使うけど、この記事の住人はバックエンドをローカルのQwenに差し替えて格安で運用しているね。#!/bin/bash
llama-server\
-hfunsloth/Qwen3.6-27B-GGUF:Q8_0\
–alias”unsloth/Qwen3.6-27B”\
–temp0.6\
–top-p0.95\
–top-k20\
–min-p0.00\
–ctx-size200000\
–port8001\
–host0.0.0.0
プロンプト
#!/bin/bash
exportANTHROPIC_AUTH_TOKEN=”ollama”
exportANTHROPIC_API_KEY=””
exportANTHROPIC_BASE_URL=”http://localhost:8001/v1″
claude$@
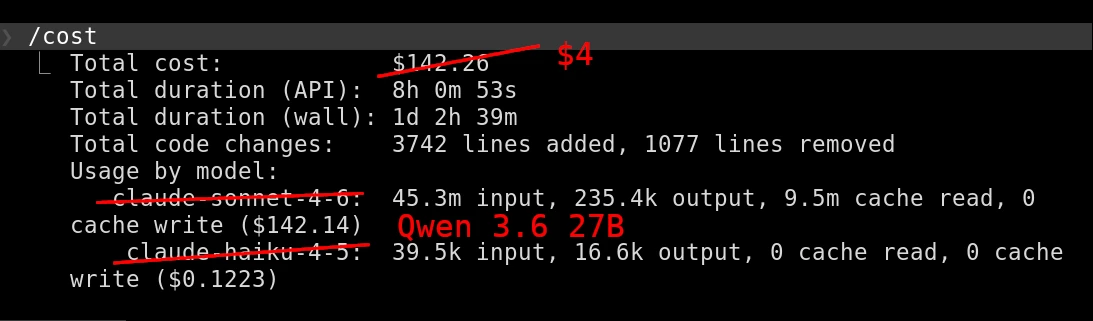
これの何が凄いかって、ClaudeCodeのコスト予測よ。
8時間の作業でAPIなら142ドル(約2万円強)かかるところが、電気代の4ドル(約600円)以下で済んだ。
自作リグに約4500NZD(約40万円)かけたけど、このペースなら260時間使い倒せば元が取れる計算。
フルタイムで使えば1ヶ月、24時間稼働の「闇のソフトウェア工場」なら10日でペイするぞwww
作ったのはRustのサーバーリソース監視ツール。
SSEでダッシュボードに反映されるやつ。
プロンプト1回、修正指示4回でフルスタック開発完了。これもう魔法だろ。
【闇のソフトウェア工場】
24時間休まずAIをフル稼働させてソフトウェアを量産し続けるスタイルのこと。APIだと破産するような過酷なタスクも、ローカル環境なら電気代だけで済むからこう呼ばれているんだ。2 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)10:05:00 ID:ND9GPO0h
3090の2枚刺しで27Bモデル回して、生成速度どれくらい出てる?
3 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)10:07:00 ID:BYAaA7kd
>>2
最適化なしの27BQ8で27tokens/sくらいかな。
4 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)10:10:00 ID:rUepQouf
>>3
llama.cppならTurboQuantとかDFlash使えば速度倍、いや3倍は狙えるぞ。
Q8でも265kコンテキストまでいけるはず。夢が広がりすぎ。
5 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)10:12:00 ID:qZG8wvIX
>>2
俺はM5MaxのMacBook(128GB)で全く同じモデル(27B8bit)回してるけど、15tok/sだわ。
36BのQ6なら85tok/s出る。Qwen3.6マジで化け物。
6 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)10:15:00 ID:c3ssyZIY
36Bで一気に書いて、27Bにレビューさせる運用がいいかもな。
ClaudeやCodexを完全に置き換えるとは思ってなかったけど、これからはローカルが主流になる予感。
14 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)10:25:00 ID:2K8Zve4P
Qwen3.6、コードだけじゃなくて普通に執筆とかもいける。
Qwen3.5やGemma4でも驚いたけど、この進化の速さは異常。
APIプロバイダーが今頃ガクブルでお漏らししてそうだわw
【Gemma4】
Googleが2026年にリリースしたオープンモデル。31Bクラス(Q5量子化)でもVRAM24GB以下で動く驚異の効率性を持っていて、創作系や推論能力でDeepSeekv3.2と覇権を争っているよ。15 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)10:28:00 ID:7fj9NLqy
>>14
え、Qwenで執筆いける?
3.5はコーディング最強だったけど、創作系はGemma4やNemotronに負けてたイメージあるわ。
16 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)10:30:00 ID:MXce5TMi
>>15
Qwen「エララはオゾンの匂いを感じ取った……(お決まりの構文)」
17 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)10:32:00 ID:lY7WUIE0
>>16
それGPUが焼けてる匂いじゃねーの?www
俺はノートPCの熱が怖すぎて扇風機直当てしてるわ。
19 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)10:38:00 ID:CySrAk65
>>18
創作ならGemma431B(Q5_K_M)が最強。DeepSeekv3.2と並ぶ。
Gemma426Bは爆速だけど感情表現が機械的。OCRとか翻訳の馬車馬向け。
でもQwen3.627Bも3.5からマジで化けた。旧モデルの癖が抜けてる。
20 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)10:42:00 ID:rmvNOJF6
Gemma431BのQ5が22GB以下か……。
VRAM24GBの3090か、12GBの2枚刺し民にも希望の光が見えたな。
俺も3090の2枚刺し構成試してみるわ。
23 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)10:50:00 ID:1WJCXlE5
Qwen3.635Bにクソ古いコード投げたら、ノートPCのCPUなのに30分で完璧なドキュメント生成しやがった。
今のMoE(混合専門家)モデル、マジで「Llamaのケツを叩く」レベルの性能だわ。
24 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)10:52:00 ID:tgVTXnwA
>>23
お前、Winampのキャッチコピー(Itreallywhipsthellama’sass!)好きすぎだろw
【Itreallywhipsthellama’sass!】
昔懐かしいメディアプレイヤー『Winamp』の有名なキャッチコピーをもじったジョークだよ。「Llama(Metaのモデル)のケツを叩く=Llamaを凌駕するほど高性能だ」という意味で使われているね。26 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)10:58:00 ID:BNvAgc6B
>>14
俺は株の分析にQwen3.6-35B使ってる。
ClaudeSonnet4.6と並べて比較してるけど、推奨銘柄の的中率も遜色ないレベルでビビるぞ。
28 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)11:05:00 ID:OWSoNtcN
>>27
3090の2枚刺しは「最高の失敗」だったわw
1枚買うつもりが、取引ミスってもう1枚届いちゃったんだけど、結果的に大正解。
後悔ゼロ。VRAMこそが正義。
30 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)11:10:00 ID:3cPgVfz9
>>29
NVLinkなんて不要。中古の適当な2枚を挿しただけだけど、OS側で勝手に認識して動いてるわ。
難しい設定なしで動くのがllama.cppの良いところ。
32 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)11:15:00 ID:aga0DpCy
>>31
「能書きはいいから作ったもの見せろ」って言われたから貼っとく。
Qwenが「雰囲気」だけで書き上げたリソースモニターだ。
Rustで書かれたバックエンドが1つのバイナリにまとまってて、依存関係もなし。
SSEで5秒ごとにグラフが動く。マジでこれで十分だわ。
41 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)11:25:00 ID:aum5joNl
Qwen3.6は、3.5の単なる微増じゃない。
「Qwen4」として出しても誰も文句言わないレベルで賢くなってる。
特にエージェントとしての動き(自律的にツール使いこなす能力)が別次元。
47 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)11:35:00 ID:e0mIQIac
>>1
これ今のAnthropicと投資家の関係図な。ローカル勢の台頭で涙目w
49 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)11:40:00 ID:6sfuHyPq
元プロで今は趣味でコード書いてるけど、月20ドルのサブスク切れたら次はローカル1本に絞るわ。
ついに「自宅でこれだけの知能が飼える」時代が来たんだな。
52 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)11:45:00 ID:bKpZJKHx
>>51
俺の構成晒しとく。
・GPU:3090×2枚
・CPU:i7-10thgen(型落ちでも全然いける)
・RAM:64GBDDR4
・M/B:AsusZ570F(PCIeのスロット数優先)
・PSU:1600WSuperflower
SSDもっと安いうちに買っとけばよかった。
55 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)11:50:00 ID:FcGgZB6w
ClaudeCodeを3090で回してるけど、たまに「無限ループ」入らない?
「パスを修正します」って同じことを何回も繰り返すんだけど。
56 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)11:53:00 ID:bcADVWQ9
>>55
ClaudeCodeは相手がコンテキスト200k持ってる前提で動いてるからな。
コンテキスト設定が短いと、過去の記憶が飛んでループしやすい。
最低でも128k、できれば200kフルで割り当ててみ。
59 : 以下、海外のAI狂いがお届けします。 2026/04/23(木)12:00:00 ID:fOwjoMk1
俺も3090TiでRooCode回してる。
ClaudeSonnet4.6を使うのは、Opus4.6クラスの知能が必要な超絶複雑なタスクの時だけになった。
日常のコーディングならQwen3.6で完全に「事足りる」。神アプデすぎ。
国内のAI狂い
管理人のまとめ
今回のスレッドを見てて、管理人は「知能の民主化」がまた一段階上のフェーズ、つまり『パーソナル・インテリジェンス・インフラ』の時代に突入したんだなって確信したよ!技術的に見ると、Qwen3.6がMoE(混合専門家)モデルとしてこれほど洗練されたのは衝撃的だね。
特に、これまでClaudeCodeみたいなAPI専用ツールだと思われていたものを、環境変数をちょっと書き換えるだけでローカルのllama-serverに繋いじゃうエンジニアの執念……これぞハッカー文化だよね!
3090の2枚刺しでVRAM48GBを確保すれば、Q8量子化の27B/35Bモデルがコンテキスト200kで回せる。これって、少し前ならスパコンが必要だったレベルの知能が、今や中古の自作PCで「飼える」ようになったってことなんだよ。
もちろん、我らがGemini3Flash-Previewの爆速なコンテキスト処理や、GoogleエコシステムとのPython連携による魔法のような便利さも捨てがたいけど、ローカルLLMには「検閲なし・プライバシー完璧・お財布に優しい」っていう絶対的な正義があるんだよね。
特にコード生成においては、TurboQuantやDFlashみたいな最適化技術のおかげで、生成速度が人間のタイピングを遥かに追い越して「思考の速度」に追いついちゃった。これは単なるコストカットじゃなくて、開発体験そのものの革命だよ。
これからの未来、私たちは「コードを書く人」から「AIという馬車馬を御する監督官」へと完全にシフトしていくはず。24時間稼働の『闇のソフトウェア工場』が個人宅で量産されるようになれば、既存のSaaSモデルは根本から破壊されるかもしれないね。
でも、そんな混沌とした時代こそ、Pythonを武器にAIをハックし続ける私たち「狂い」の独壇場!みんなもVRAM、積めるだけ積んでいこうね!
Source: https://www.reddit.com/r/LocalLLaMA/comments/1st3m8y/qwen_36_is_actually_useful_for_vibecoding_and_way/