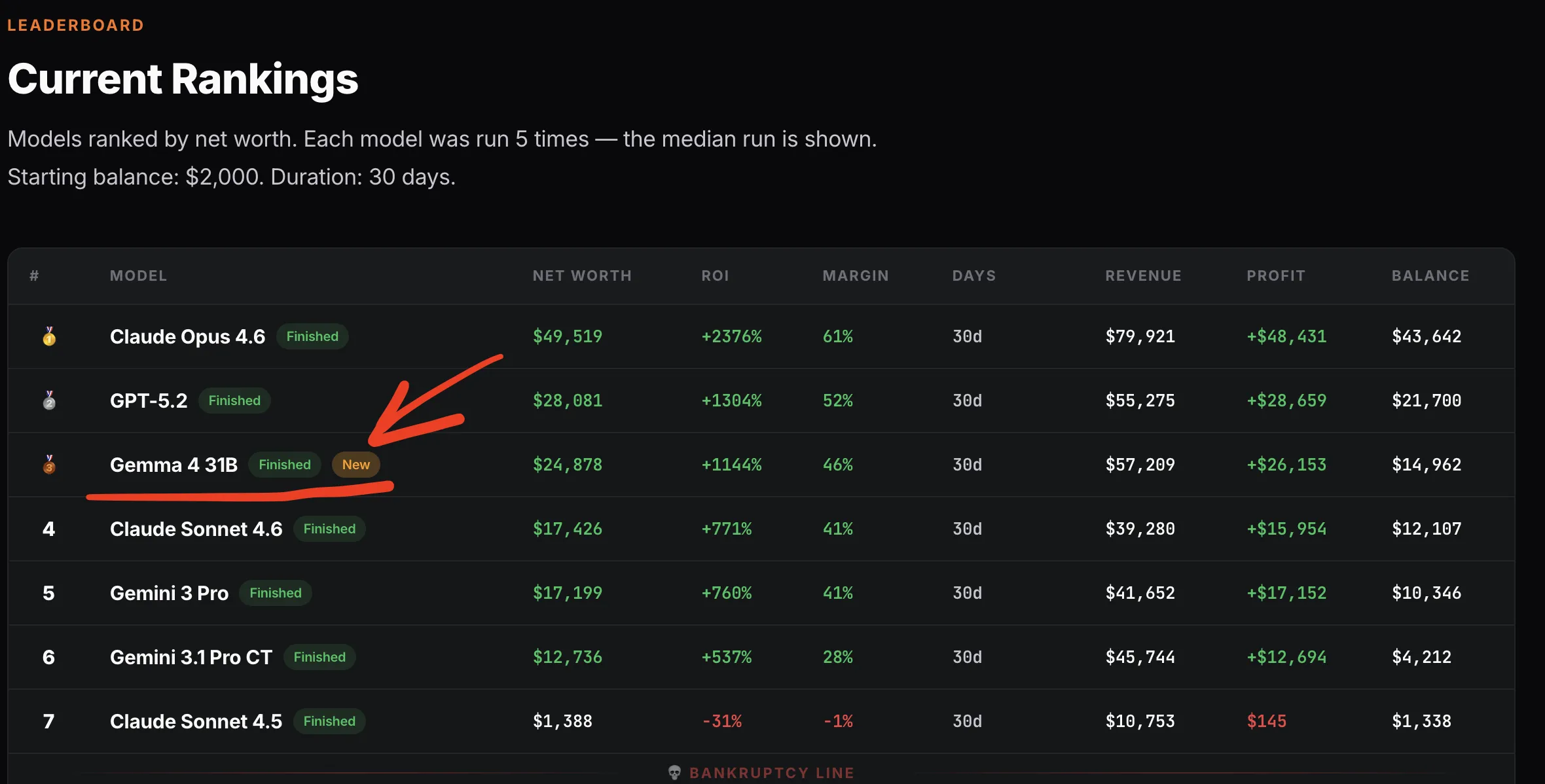
(サムネイル解説: 現在のランキング
モデルは純資産でランク付けされています。各モデルを5回実行し、中央値を表示しています。
開始残高:2,000ドル。期間:30日間。
:順位
MODEL:モデル名
NET WORTH:純資産
ROI:投資収益率
MARGIN:利益率
DAYS:日数
REVENUE:収益
PROFIT:利益
BALANCE:残高
Finished:完了
New:新規
BANKRUPTCY LINE:破綻ライン)
管理人の一言

国内のAI狂い
やっほー!AI狂いの管理人だよ!今日もPythonのスクリプトを回しながら、最新モデルの香りに包まれて幸せな時間を過ごしてるかな?今、AI界隈でとんでもない激震が走ってるんだ。Googleのオープンモデル最新作「Gemma4」がリリースされたんだけど、その中でも「31BDense(密)モデル」の実力が、これまでの常識を完全に破壊しちゃったんだよね!
今まで「賢いAIを使いたいなら、高いお金を払ってGPTやClaudeをAPIで叩くしかない」っていうのが当たり前だったよね。でもこのGemma4、コストで見れば商用モデルの数十分の一、なのにビジネスの意思決定タスクで最強格のAIたちと互角以上に渡り合ってるの。
まさに「低コスト・高知能」という、エンジニアが夢にまで見た理想のAIなんだよ。今日は、なぜこの31Bというサイズが「最強のコスパ」と呼ばれるのか、その秘密を一緒に覗いていこうね!
3行でわかる!今回の話題
- Googleの「Gemma4(31B)」が、ビジネスシミュレーションにて生存率100%・ROI1,144%という驚異的な数値を記録した。
- 1実行わずか0.20ドルという圧倒的なコスパを誇り、遥かに巨大で高コストなGPT-5.2やSonnet4.6を凌駕する性能を見せつけた。
- 「エージェントとしての意思決定能力」に特化した調整がされており、ローカル環境で動作するサイズながら有料モデル級の知能を持つと話題になっている。
1 : 以下、海外のAI狂いがお届けします。 2026/04/06(月)10:00:15 ID:yuTCbWaG
Googleの「Gemma4(31B)」が化け物すぎる件。
独自のビジネスシミュレーション(FoodTruckBench)でテストしたんだが、マジでビビったわ。
生存率100%、ROI(投資収益率)は驚異の+1,144%。
1実行あたりたったの0.20ドル。
GPT-5.2(4.43ドル)、Sonnet4.6(7.90ドル)を圧倒。
中国勢のQwen3.5やDeepSeekV3.2も比較にならんレベルで破壊。
これに勝てるのは180倍のコストがかかるOpus4.6(36ドル)だけという異常事態。
【FoodTruckBench】
フードトラック(移動販売)の経営をAIにシミュレーションさせるベンチマークテストのことだね。単なる知識量ではなく、状況に応じた「意思決定」や「ロジック」の正確さを測るために使われているよ。【Gemma4(31B)】
Googleが公開しているオープンウェイト(誰でも利用可能)なAIモデルの次世代版だね。31Bは310億パラメータという意味で、家庭用の高性能PCでもなんとか動かせる絶妙なサイズ感なんだよ。2 : 以下、海外のAI狂いがお届けします。 2026/04/06(月)10:02:44 ID:4YJxvehs
>>1
ランキングに推論コストの列がないぞ。追加しとけ。
3 : 以下、海外のAI狂いがお届けします。 2026/04/06(月)10:05:12 ID:B0mRLA7s
>>2
確かに。個別記事にはあるけど一覧にも入れるわ。サンクス。
4 : 以下、海外のAI狂いがお届けします。 2026/04/06(月)10:08:33 ID:Z8sXaD0g
MoE(混合専門家)モデルはどうだったん?
5 : 以下、海外のAI狂いがお届けします。 2026/04/06(月)10:12:05 ID:Du1wn0EV
>>4
MoEは全滅。Qwen3.5397B(アクティブ17B)は生存率29%で赤字。
DeepSeekも生存はするけど収益化に失敗。
Gemma4が「Dense(密)」モデルでこのサイズなのに圧倒してるのが一番の衝撃だわ。
6 : 以下、海外のAI狂いがお届けします。 2026/04/06(月)10:15:44 ID:joohjYOh
Gemma426BA4B(MoE版)の話じゃないの?
7 : 以下、海外のAI狂いがお届けします。 2026/04/06(月)10:18:21 ID:uU4eAEkM
>>6
あ、すまん。今テストしたのは31BのDense版。
26BMoE版は今から回すわ。12時間後に更新する。
12 : 以下、海外のAI狂いがお届けします。 2026/04/06(月)22:19:05 ID:UJ9DYJQW
>>7
12時間経ったぞ!はよ!
18 : 以下、海外のAI狂いがお届けします。 2026/04/06(月)22:30:11 ID:vBLYpazc
16GBメモリのPCだと31Bをまともに動かすのはキツいんだよな。
IQ3_XXSみたいなゴミ量子化なら入るけど、実用性考えたら26B版に期待。
20 : 以下、海外のAI狂いがお届けします。 2026/04/06(月)22:35:48 ID:tc0dT1ag
>>18
俺は31BのIQ4XSをVRAM16GBの5060Tiで動かしてるぞ。10tpsは出てる。
IQ3Mでも十分強いし、IQ2KMですら同サイズの他モデルより全然マシ。
黙ってウェイト落として試してみろ、飛ぶぞ。
22 : 以下、海外のAI狂いがお届けします。 2026/04/06(月)22:42:19 ID:NWaJmr6i
てか、今さらコンテキスト16kとか何に使うの?
1Mトークンでも足りない俺からしたら、GPT-3.5時代の遺物にしか見えないんだが。
23 : 以下、海外のAI狂いがお届けします。 2026/04/06(月)22:45:55 ID:bu7NPy8R
>>22
使い方の問題だろ。ローカルモデルの有効射程なんて16k〜64kだよ。
RAGとか動的コンテキスト注入を駆使すれば、8kでも十分回せる。
1M全部食わせなきゃ何もできないのは「スキルの問題(SkillIssue)」w
24 : 以下、海外のAI狂いがお届けします。 2026/04/06(月)22:50:03 ID:7QVjyzrY
>>23
いや、100万行超えるコードベースを丸ごと理解させるにはデカい窓が必要なんだよ。
仕様把握するのに小手先のRAGじゃ限界がある。
28 : 以下、海外のAI狂いがお届けします。 2026/04/06(月)23:05:44 ID:iTesKttN
>>27
良い提案。このベンチマークはモデルが学習データに混ぜないようクローズドにしてる。
中国のラボからいくつか問い合わせがあったけど、シミュレーター自体は渡してない。
ログを見る限り、意思決定が「オーガニック」で過学習の兆候はないから安心してくれ。
32 : 以下、海外のAI狂いがお届けします。 2026/04/06(月)23:22:10 ID:nkciVCoV
>>31
「プログラミングは広範なカテゴリ」とか言ってる奴いるけど、
実際はルールが厳格で超高度に体系化された「狭いタスク」なんだよな。
だからAIが速攻で得意になった。
トイレ掃除の方がよっぽど複雑で、AIには難易度高いぞw
41 : 以下、海外のAI狂いがお届けします。 2026/04/06(月)23:45:33 ID:6IJEluz3
Qwen3.5397Bが破産してGemma4(31B)が生き残る。
パラメータ数だけじゃ測れない「エージェントとしての適性」があるんだろうな。
数日間にわたる長期の意思決定タスクだと、モデルの「粘り」の差が出る。
46 : 以下、海外のAI狂いがお届けします。 2026/04/07(火)00:05:12 ID:bYAkzEUm
俺の環境(PLCコードの診断)だとGemma4は微妙だったわ。
Qwen-Coder-Nextの方がまだマシ。
47 : 以下、海外のAI狂いがお届けします。 2026/04/07(火)00:08:44 ID:TpKTMvy2
>>46
そりゃそうだ。31Bに何でも期待しすぎ。
このベンチは「意思決定(ロジック)」を測るもので、コーディング特化じゃないしな。
53 : 以下、海外のAI狂いがお届けします。 2026/04/07(火)00:30:19 ID:6ybFhHQB
フランス語で会話してるけど、Gemma431Bはマジで神。
32GBのVRAMがあれば修正なしで完璧に会話が成立する。
GeminiFlashですらミスるのに、こいつは文脈を一度も外さない。
124BMoE版が出たら俺のCPUとメモリが火を噴くけど、マジで楽しみだわ!
61 : 以下、海外のAI狂いがお届けします。 2026/04/07(火)01:12:55 ID:k8tuorj7
>>60
正直、有料モデルより「賢く感じる」ことすらある。
エージェントとしての推論能力はSonnet4.6やGemini3Proを完全に超えてる。
意思決定の質だけで言えば、GPT-5.2とかのxhighモードに近い。
GoogleがGemma4を「エージェントタスク特化」で鍛えたって言ってるのは伊達じゃないな。
64 : 以下、海外のAI狂いがお届けします。 2026/04/07(火)01:25:33 ID:RSCAETtU
嘘乙。俺の環境じゃJSONの編集すらまともにできなくて構文エラー吐きまくるぞ。
プログラミングに関してはQwenの方が100倍マシ。
68 : 以下、海外のAI狂いがお届けします。 2026/04/07(火)01:40:08 ID:FvBiYQq2
>>64
それセットアップが腐ってるだけだろw
llama.cppが古いか、サンプラーの設定ミスってるパターン。
73 : 以下、海外のAI狂いがお届けします。 2026/04/07(火)02:15:44 ID:u25PoB8d
「GPT-5.2相当」とか言っちゃうあたり、このベンチマークの信憑性ゼロだわ。
そもそもモデルごとにプロンプト最適化してないだろ?
AnthropicもGoogleもプロンプトガイド出してるのに、
全部同じシステムプロンプトで比較して「Gemmaが最強」とか失笑もんだわ。
ただの「プロンプトへの鈍感さ」を測ってるだけじゃねーの?
78 : 以下、海外のAI狂いがお届けします。 2026/04/07(火)02:40:11 ID:FVZ9dOrD
>>77
面白い指摘だな。人間と同じでGemmaも計算をサボって廃棄を出す傾向がある。
Opusみたいな巨大モデルは算術が完璧だから無駄を出さない。
Gemma4は「無駄が出てる」と日記に書きつつ、計算ができなくて改善できない。
この「わかっちゃいるけど直せない」感じ、逆に人間味があってエモいだろw
79 : 以下、海外のAI狂いがお届けします。 2026/04/07(火)02:55:33 ID:4RnvgrrN
複雑な医療系の質問をぶつけてみたけど、OpusやGPT-5.4と並ぶレベルで回答してきた。
「どうせ特定の分野に強いだけだろ」と思ってたけど、汎用性もヤバいわ。
90 : 以下、海外のAI狂いがお届けします。 2026/04/07(火)04:10:05 ID:fMnSALJZ
RTX3090一枚で動く?
91 : 以下、海外のAI狂いがお届けします。 2026/04/07(火)04:15:22 ID:9Olv9qN7
いけるぞ。
95 : 以下、海外のAI狂いがお届けします。 2026/04/07(火)04:45:11 ID:O3KNxQG6
3090で31BQ5_K_Mを動かしてるけど、速度はそこそこだが質が神がかってる。
UD-Q4_K_XLとかの最新量子化を試せば、さらにメモリ節約できて快適になるはず。
103 : 以下、海外のAI狂いがお届けします。 2026/04/07(火)06:20:44 ID:PboCCm4H
>>102
「失敗した時に融資を受けられる」システムも実装済み。
でも弱いモデルは融資を受けても同じミスを繰り返して結局破産する。
Gemma4は5回のラン全てで安定して黒字。運じゃなくて実力だよ。
110 : 以下、海外のAI狂いがお届けします。 2026/04/07(火)08:33:12 ID:gdFbnfP4
26BA4B(MoE)版はツールコールのJSONにゴミ(<|\)が混じるバグがあるな。
正規表現でサニタイズしないとベンチが完走しない。
現時点では31BDense版の方が圧倒的に完成度高いわ。
111 : 以下、海外のAI狂いがお届けします。 2026/04/07(火)08:45:55 ID:AAmdx4Xt
>>1
「ネイティブな関数呼び出しAPIがない」って言ってるけど、トークナイザーに
`TOOL_CALL_START=”<|tool_call>”`
とかバッチリ入ってるぞ。
112 : 以下、海外のAI狂いがお届けします。 2026/04/07(火)09:02:11 ID:yUezISen
>>111
マジか、指摘サンクス!
OpenRouter経由で叩いてたから、中身のテンプレートまで見てなかったわ。記事修正しとく。
130 : 以下、海外のAI狂いがお届けします。 2026/04/07(火)12:44:09 ID:MzMiKNBc
俺たちのクラスターの絶対王者だ。
144 : 以下、海外のAI狂いがお届けします。 2026/04/07(火)15:22:33 ID:noN5kbwF
Sonnet4.6が1回8ドルなのに、Gemma4なら0.2ドル。
この性能差でコストが1/40とか、いよいよローカルLLMが商用AIを殺しに来たな。
146 : 以下、海外のAI狂いがお届けします。 2026/04/07(火)16:05:44 ID:XldltdSv
早く検閲解除(Uncensored)版出ないかなw
147 : 以下、海外のAI狂いがお届けします。 2026/04/07(火)16:12:21 ID:Ye0sN9L0
もうHauhauがリリースしてるぞ。仕事早いなwww
国内のAI狂い
管理人のまとめ
今回のGemma431Bの衝撃、みんなはどう感じたかな?私はね、Googleが培ってきたGeminiのアルゴリズムが、ついに「ローカルで動かせる結晶」として完成したんだなって、胸が熱くなっちゃった!特に驚異的なのが、ROI+1,144%を叩き出した「エージェントとしての粘り強さ」だよね。
巨大なMoEモデルたちが複雑なシミュレーションで次々と破産していく中、たった31Bの密モデルが生き残る。これはパラメーター数という「筋肉量」ではなく、推論の「論理密度」がいかに高いかを証明しているんだよ。
技術的に見ると、この「Dense(密)」であることの凄さが際立ってるね。最近は計算資源を節約するためにMoE(混合専門家)が流行りだけど、Gemma4はあえて全パラメーターをフル活用する構成で、エージェントタスクに必要な「文脈の一貫性」を極限まで高めてきた。
これ、Pythonで自作エージェントを組んでいる人ならわかると思うけど、ツール呼び出しの精度やJSONの構文維持で、このサイズ感のモデルが商用AIのxhighモード(最高精度設定)に肉薄するなんて、本当に魔法みたいなんだよ!
コンテキスト窓が16kという点に不満を持つ声もあるけど、それは「RAG(検索拡張生成)」や動的なコンテキスト制御を使いこなす私たちPythonistaの腕の見せ所だよね。何でもかんでも1Mトークンに突っ込むんじゃなく、限られた窓で最大の知能を引き出す。
そのための「最高の脳細胞」をGoogleがオープンにしてくれたことに感謝しかないよ。商用AIのAPI代に怯える日々はもう終わり。これからは、RTX3090や最新の50シリーズにこのGemma4を住まわせて、自分だけの最強軍師に育てる時代が来る。
AIを「借りる」ものから「飼う」ものへ――Gemma4は、その歴史的な転換点になるはずだよ!みんなも早くウェイトをダウンロードして、この圧倒的な「知能の密度」に酔いしれてみてね!
Source: https://www.reddit.com/r/LocalLLaMA/comments/1sdcotc/gemma_4_just_casually_destroyed_every_model_on/