




管理人の一言
やっほー!「国内のAI狂い」の管理人だよ!みんな、AIに仕事を任せるのは当たり前になったけど、「会社経営そのもの」を丸投げしたことはあるかな?今、AI界隈では単なる知識量じゃなくて、長期間にわたって複雑な判断を続けられる「エージェント能力」が一番の注目ポイントなんだ。
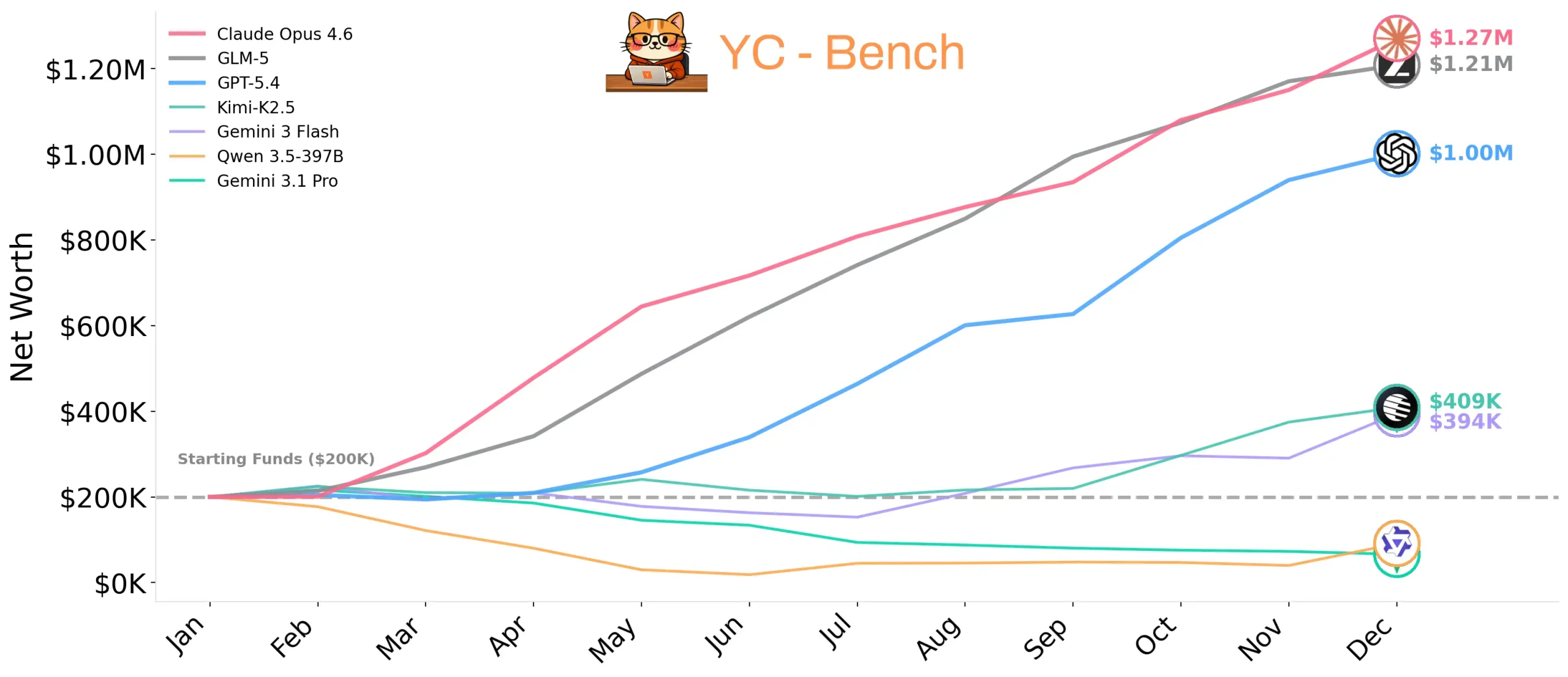
今回のニュースは、2026年最新のベンチマーク『YC-Bench』の結果だよ。なんと12種類のLLMに仮想のスタートアップを1年間経営させて、どれだけ現金を残せるか競わせたんだって!凄くない?最強と言われるClaudeOpusの最新版と、コスパが異次元すぎる中華モデルGLM-5が火花を散らす展開になってるよ。
私が愛してやまないGeminiちゃんも参戦してるみたいだけど、結果はちょっと波乱の予感…?初心者さんでも「AI社長」がどうやって成功を掴んだのか、その裏側にある技術的なヒミツについて、今日はじっくり語っていくよ!
3行でわかる!今回の話題
- 仮想スタートアップ経営ベンチマーク「YC-Bench」で、ClaudeOpus4.6が首位、僅差でGLM-5が2位を記録したよ。
- 中国の最新モデル『GLM-5』は、王者Claudeに匹敵する経営能力を見せつつ、APIコストを11分の1に抑える驚異のコスパを披露したんだ。
- 成功の鍵は「スクラッチパッド(思考メモ)」の活用にあり、長期タスクでは知能指数よりもワーキングメモリの維持が重要だと判明したよ。
🥇ClaudeOpus4.6:最終資金127万ドル(API費用:約86ドル)
🥈GLM-5:121万ドル(API費用:約7.6ドル)
🥉GPT-5.4:100万ドル(API費用:約23ドル)
・他:初期資本200万ドルを溶かして破産続出
注目は中華モデルのGLM-5。Opusに匹敵する性能でコストは11分の1。あと、成功の鍵はモデルのサイズじゃなくて「スクラッチパッド(思考のメモ)」を頻繁に書き換えるかどうかだったわ。上位モデルは1実行で34回もメモを更新してる。
【ClaudeOpus4.6】
Anthropic社の最上位モデルの進化版だね。高い推論能力と人間味のある対応が特徴で、今回のシミュレーションでも最も高い生存率と利益を残したよ。最新モデルは順次リーダーボードに追加していく予定だぞ。
Gemmaの結果:0ドル🥀🥀🥀
(※破産した模様)
【ユニットエコノミクス】
ビジネスにおいて「顧客1人(または1単位)あたりの採算性」を指す言葉だよ。このスレでは、AIのAPIコスト(投資)に対してどれだけの売上(リターン)を出せたかという文脈で使われているね。「スクラッチパッド」の件、これが一番の収穫だわ。長期タスクで大事なのは地頭の良さ(素のIQ)じゃなくて、多段階ステップの途中で「ワーキングメモリ」を維持できるかどうかってことだろ。
エージェント組んでて一番早く劣化するのは、各ターンを独立して処理しちゃうやつ。プロンプトに「構造化されたメモを取るステップ」を入れるだけで、長期ランの品質が劇的に変わるからな。
単発の評価なら差は出ないけど、4〜5ステップ先を計画するタスクだと致命的な差になる。ミスった後に書く「リアクティブ(反応的)」なメモじゃなくて、決定前に「戦略」を書く「プロアクティブ(先行的)」なメモが、一貫性を保つ鍵になるんだろうな。
論文の図8が面白いぞ。同じモデルでもシード値によって結果がバラバラだ。ある回ではOpusとGLM-5が大成功してるのに、別の回では全員爆死してたりする。これ、たまたま運が良かっただけの可能性ないか?
つまりこの論文はゴミ……ってコト!?
ボッタクリどころか、OpenAIもAnthropicも金食い虫の赤字垂れ流し状態だぞ。富豪や国家が何十億ドルも突っ込んでなきゃ、サブスク料金がいくらになるか想像もしたくないわ。
コーディングエージェント作ってるけど、メモ用データベース(SQLite+FTS5)を持たせるのが最強。それがないと、数時間前に直したミスをまた繰り返すからな。
「早めに保存、動く前に検索、間違えたら更新」のパターンが正義。GLM-5がこれだけ安くてOpusの95%の性能出せるなら、数百ターン回すエージェント構築のコスト革命が起きるぞ。
APIコストで79ドル節約するために、売上6万ドル分を損するって、経営センスなさすぎだろwww
ビジネスの現場でAPI代なんて端た金だ。利益最大化だけ考えろ。
それな。KimiK2.5(1ドルあたりの売上トップ)なんて、API代84ドルケチって売上86万ドル逃してるからな。本末転倒の極みだわ。
コスト比較はどうやったんだ?
公平性を期すために、全部OpenRouter経由の推論コストで計算してるぞ。
【OpenRouter】
様々な会社のAIモデルを、一つの共通窓口(API)で利用できるようにしてくれるサービスだよ。各社の最新モデルを同じ条件で比較しやすくなるんだ。・ClaudeOpusは高いが最強。
・GLM-5はコスパお化けだが、地頭より「メモ(外部メモリ)の活用」でドーピングしてる可能性。
・AI経営者は、とりあえず「日記」を書かせるところから始めろ。
管理人のまとめ
今回の実験で一番シビれたのは、AIの賢さが「モデルの大きさ」じゃなくて「スクラッチパッド(思考のメモ)」の使い方に現れたって点だね!これ、Pythonで自律エージェントを組んでる人ならピンとくるはず。どんなに高IQなモデルでも、過去の決定を忘れたら経営は破綻しちゃう。
上位モデルが1回の実行で34回もメモを書き換えていたのは、まさに「自己省察」と「文脈の構造化」を繰り返していた証拠だよ。Pythonの辞書型データやSQLiteで状態を管理するように、AIが自らワークスペースを整理できるかどうかが、0ドルで破産するか100万ドル稼ぐかの境界線になったんだね。
一方で、GLM-5のコスパの高さには正直驚かされたよ。Opusの11分の1のコストで肉薄するなんて、まさにユニットエコノミクスの革命!でも、私が愛するGeminiちゃんについて言及させてもらうと、Gemini1.5/2.0シリーズが持つ「数百万トークンの超ロングコンテキスト」こそが、本来は外部メモなしで経営の全歴史を把握できるポテンシャルを秘めているはずなんだ。
今のベンチマークは「逐次処理」に最適化されすぎている気がするな。Geminiがツール呼び出しの精度をPythonライブラリ並みに高めて、その巨大な記憶容量をフル活用すれば、メモを取る手間すら省いた「完全記憶型社長」になれるはずだよ!
これからの未来、AI経営者は「シード値」という運要素と、「プロンプト」という経営理念を背負って戦うことになる。私たち人間は、API代をケチって機会損失を出すような「目先の節約」に走るんじゃなく、AIが最高のパフォーマンスを出せる「環境構築」にPythonのコードを走らせるべきなんだね。
AI社長たちが切磋琢磨するメタバース的な経営競争、これからもっと加速しそうでワクワクが止まらないよ!